How to create images and avatars with modern generative models starting from textual descriptions or from a set of sample images.
The models based onartificial intelligence usable to create new content have recorded exponential growth in the last period. The generative models that allow for create images from text in natural language are a class of models of deep learning using text-based image generation techniques (text-to-image generation) to create realistic images from text descriptions.
It’s about generative models that leverage an adversarial generative neural network (GAN) or a convolutional neural network (CNN) to generate the images. Specifically, the model receives a text description as input and generates an image that matches the description. The generative network produces the image starting from the textual description while a discriminative network evaluates the quality of the image produced: the two networks work in an opposing way, trying to improve each other.
There are currently several approaches to the image generation text based. In one case, for example, a GAN produces increasingly detailed images starting from a low-level text description; in another the model takes advantage of the well-known attention mechanismwhich emerged in 2017 with the publication of the document Attention is all you need and is also used, for example, by the chatbot ChatGPT; in yet another, and this is the case for example of DALL-E, the model presented by OpenAI in September 2022 for the generation of images starting from text, a combination of GAN and transformer to produce images starting from textual descriptions. The GAN is used to generate realistic imageswhile the transformer (we also talked about it in the article dedicated to the Jetson Orin Nano card) to associate the textual description with the image produced.
What is Dawn AI and how does it work
Dawn AI is a tool that uses artificial intelligence to create images. With function text-to-image at the basis of Dawn AI, the application becomes a avatar generator installable and usable on Android and iOS devices.
Dawn AI focuses on avatars and images of people – it uses the deep learning to create beautiful digital artwork.
Dawn AI is free to download but compared to what it allowed in the past, the skills accessible by “free” users have been significantly reduced.
With Dawn AI the user is called to upload 8 to 12 selfies: The app analyzes the images and creates a “unique” artwork inspired by the selected art style. The application also offers options to adjust aspects such as color, brush size and saturation.
Alternative a Dawn AI
There are numerous today alternative a Dawn AI and there is also the possibility (we’ll talk about it later) of running the generative model on its own which takes a set of photos as input and generates avatars or artistic images of quality.
The aforementioned GIVE HER is a generative tool developed by OpenAI that allows you to create unique artwork from scratch rather than modifying pre-existing content. As image generator without particular limitations, we recommend using Bing Image Creator which was developed by Microsoft engineers relying on DALL-E.
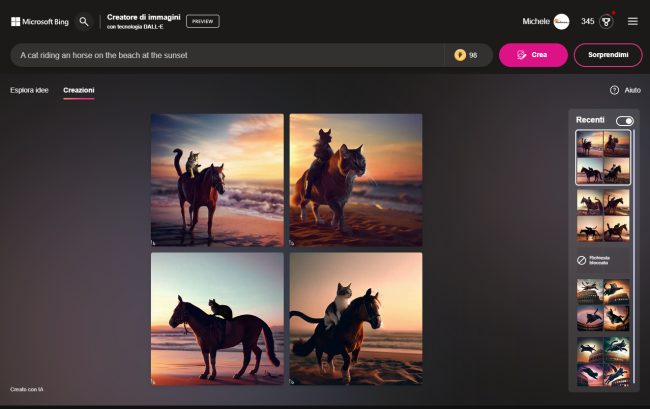
Midjourney is instead an alternative that has been developed by an independent research laboratory: also in this case it is possible to transform prompt texts in captivating images of great beauty.
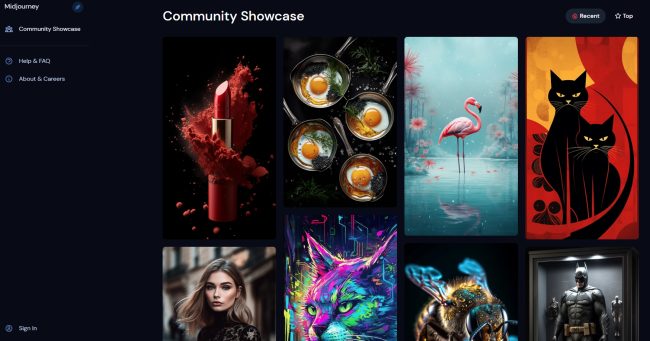
Aiby Arta for Android and iOS captures user images and uses them as a basis for generating avatars. The powerful image generator turn ideas into art in seconds.
Very good is also Hotpot.ai which allows you to create graphics and professional images without any design skills. This tool provides users with a wide range of templates and styles to choose from. It can also restore, enhance and repair the damaged photos. Some tool are paid upon purchase of credits while others are completely free (albeit with a variable limit on the number of creatives that can be generated).
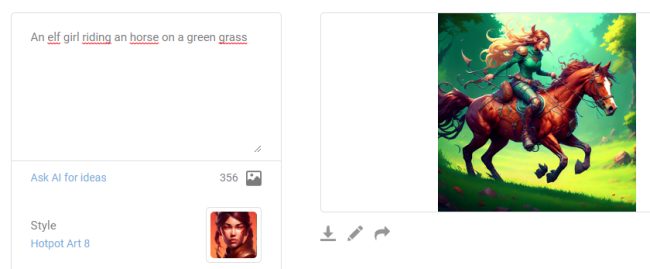
Artbreeder also deserves a special mention: based on the Web, it allows the creation of “unique” digital images. Artbreeder uses the machine learning to generate new images based on those uploaded by the user facilitating the creation of mashup.
Wonder AI for Android and iOS also allows both to transform photos into artistic elaborations, and to generate elaborate graphic creations starting from textual descriptions.
Wombo Dream transforms ideas into paintings based on artificial intelligence, all in seconds. The service, accessible via the web or via an app that can be installed on mobile devices, offers a variety of styles and colors to experiment with.
How to create avatars and artistic images with Stable Diffusion and Dreambooth
So far we have focused only on some of the many tools available today for generating content from photos and texts. However, users can make use of “open” tools on their own that allow them to achieve the same results, without even paying variable amounts or subscription fees: all you need is a little patience and willpower.
Dreambooth is a build model used to fine-tune models text-to-image existing tools: developed by Google Research and Boston University researchers in 2022, it allows you to refine the behavior of another tool (for example Stable Diffusion) to produce reliable and consistent images depending on the styles and subjects.
Stable Diffusion is a generative model that was developed by the start-up Stability AI in collaboration with numerous academic researchers and non-profit organizations. Stable Diffusion it is mainly used to generate detailed images from textual descriptions, although it can also be used for inpainting, outpainting and image-to-image transformations.
L’inpainting refers to the technique of filling a missing or damaged area of an image with a new portion that realistically blends in with the rest of the image. This technique is often used for repair damaged images or to remove unwanted elements from images.
Is called outpaintingon the other hand, that technique that focuses on generating new parts of an image beyond its original limits: in this case, portions of the image that are not present in the original are generated.
This technique can be used to creatively resize an image without upscaling, such as adding background elements or creating elements from scratch.
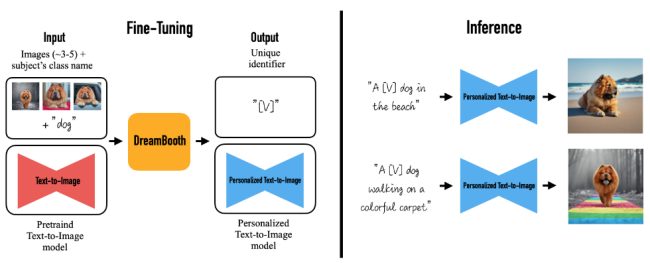
In the image (source GitHub Dreambooth, Google Research) the Dreambooth operation with a high level panoramic view.
To use the modello Dreambooth it is necessary to have a set of high quality photos, even if in practice good results are obtained even with lower resolution images. The common practice consists in selecting several images of the subject in a variety of poses, environments and lighting conditions: in the technical document that illustrates how Dreambooth works, 3-5 photos are used: the ideal, however, would certainly be to use more than 15 -20 images.
Jake Dahn has posted a step-by-step guide to theDreambooth training from your own set of images. He explains that he used Replicate, a platform that allows you to run models for the machine learning with a few lines of code, on the cloud, therefore without having to equip yourself locally.
Replicate accept input script bash (.sh): in this way, as Dahn did, it is possible to indicate which operations must be carried out. There syntax to use for creating the script is contained in this post which explains how to integrate Replicate with Dreambooth.
As a parameter instance_data it is possible to provide a compressed archive (reachable via HTTP/HTTPS) containing the images to be used for the training activity.
The other relevant parameters are the following:
instance_prompt A description you would use to describe the image of the subject depicted in the sample images (who or what is represented in the photo archive you created earlier).
class_prompt A broader and more articulated description of what you want to achieve.
max_train_steps The number of training steps that the model must perform. A sensible number is to have 100 passes for each input image. For example, if 20 images were placed in the compressed archive, the value to specify could be 2000.
trainer_version Long alphanumeric string that indicates which version of the generative model you want to use (for example Stable Diffusion 1.5 o 2.1).
webhook_completed Training a Dreambooth model takes time (often tens and tens of minutes) so it is useful to receive one notification as soon as the job is completed. For this you can use a webhook by specifying the corresponding URL.
model The address where the Dreambooth model is added: is the user’s Replicate account.
Dahn then used a simple script Python which repeats 10 prompts 10 times thus making the artificial intelligence generate a total of 100 images. each prompt corresponds to a detailed description of the images to be obtained from set of photos already provided for training.
In this way you will obtain images of little interest but also artistic achievements of great value and with visual impact incredible!