
The new playing field on which the main entities dealing with are competing generative models and, in general, of solutions based on artificial intelligence, has to do with performance optimization. Just think of SDXL Turbo, presented in November 2023 by Stability AI, and the new PixArt-δ model developed by a team of academic researchers in collaboration with Huawei (January 2024). Google decided to respond blow by blow by presenting MobileDiffusion.
What is MobileDiffusion and how does it work
The rapid image generation starting from descriptive texts (prompt) in natural language represents a real challenge, especially on mobile devices, due to the more limited computational resources that these devices can benefit from. For this reason, usually, the processing related to the applications of artificial intelligence are delegated to the infrastructure available on the cloud.
Smartphones, however, are evolving rapidly in terms of raw power, and integrating a chip is increasingly common NPU (Neural Processing Unit), a unit designed specifically to perform tasks related to artificial intelligence and machine learning. The NPU architecture is optimized for the mathematical operations involved in computations related to training and operating artificial neural networks.
Google technicians present MobileDiffusion like an efficient latent diffusion model, designed specifically for mobile devices. Uses DiffusionGAN to perform one-step sampling during the inference phase, leveraging a pre-trained diffusion model together with a GAN network to model the inference phase denoising. Too many concepts all at once? Let’s try to translate everything into a more understandable language.

In the figure, some examples of images created using the new Google MobileDiffusion model.
The latent diffusion model
Il “latent diffusion model” (LDM) is a deep machine learning model used to generate detailed images. It is a variant of diffusion model (DM) and relies on training to remove noise from images progressively. In practice, the model takes an image and adds noise in successive steps, then gradually removes it, resulting in a cleaner image.
The term “latent” refers to the latent space (we talked about it in our other articles), which is a compressed representation of the data. This approach allows you to generate detailed images and high quality using generative artificial intelligence.
What does DiffusionGAN mean
Is called DiffusionGAN the model of machine learning which combines two previously known schemes: Generative Adversarial Networks (GAN) and diffusion models. GANs are known for generating new data, such as images.
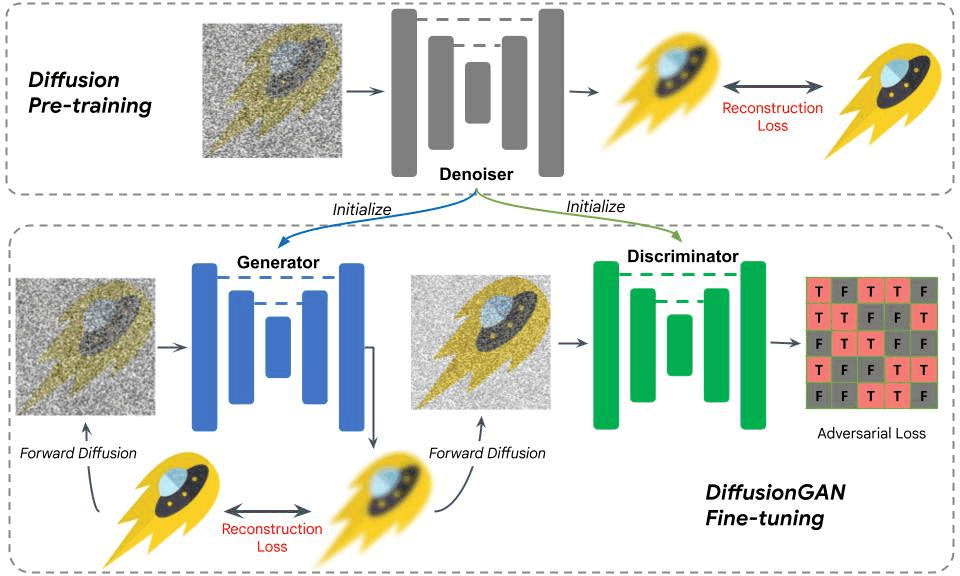
Operation diagram of the optimization with DiffusionGAN.
The goal is to combine these two techniques to generate high-quality images efficiently and with good quality data coverage. This combination offers the potential to improve the quality and diversity of images as they are generated.
The advantages of Google MobileDiffusion
Using the new MobileDiffusion, explains Google, it is possible generate images high quality (resolution 512 x 512 pixels) in just 0.5 seconds on devices premium (read the highest-end smartphones equipped with NPU…).
MobileDiffusion therefore has the advantage of being ultraperformante on mobile devices thanks to the use of three components: a text encoder, a dissemination UNet and an image decoder.
Il encoder used for text has the task of converting the prompt in a numerical representation understandable by the model. In the specific case of MobileDiffusion, Google uses a model called CLIP-ViT/L14 come encoder. It is designed to be lightweight and mobile-friendly, just resting on 125 million parameters.
UNet is a neural network architecture commonly used for image generation. In the context of MobileDiffusion, the diffusion UNet plays an important role in generating images from the numerical representation of the text obtained by the encoder.
Finally, the decoder deals with translating the numerical representation obtained from the diffusion UNet into afinal image. It is responsible for transforming the numerical representation into a form visually understandable.
MobileDiffusion coming soon to Android and iOS
Unfortunately, at least for now, MobileDiffusion remains a research project carried out by four Google researchers. The company, however, not only celebrated the important milestone set by MobileDiffusion with a post on the official blog, but also compared the performance of the model with that of the main “competitors”.
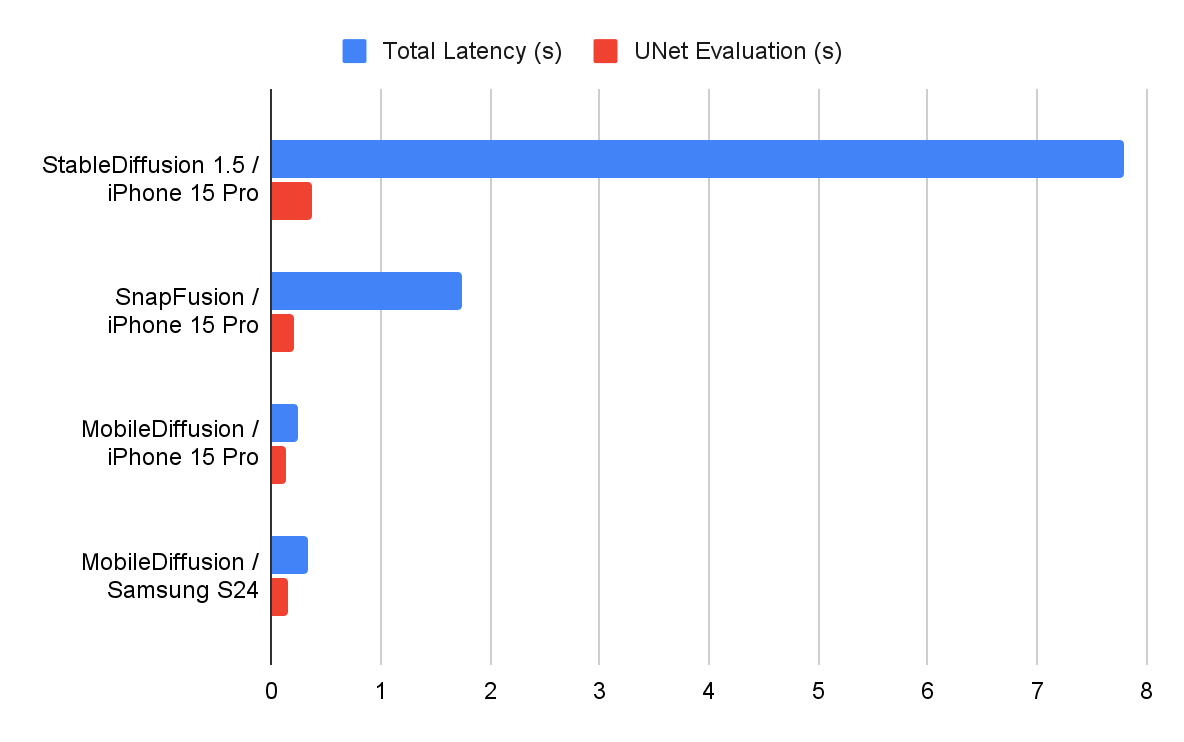
The comparison between MobileDiffusion used on smartphones is interesting Samsung Galaxy S24 e iPhone 15 Pro with performances recorded by StableDiffusion e SnapFusion on the top of the Apple range.
In conclusion, Google suggests that MobileDiffusion will be the protagonist of the solutions intended for mobile devices proposed by the Mountain View company and focused on artificial intelligence. It is in fact a “friendly” solution for those who use i modern smartphone. It will also be deployed with the utmost attention to respecting ethical aspects and responsibility in charge of Google’s AI solutions.
Image generation as-you-type
It goes without saying that the decisive push on the performance accelerator will allow the creation of apps capable of generating a series of images in real time. A possibility that opens the door to the application of arbitrary modifications on pre-existing images or on resources produced by the same generative model.
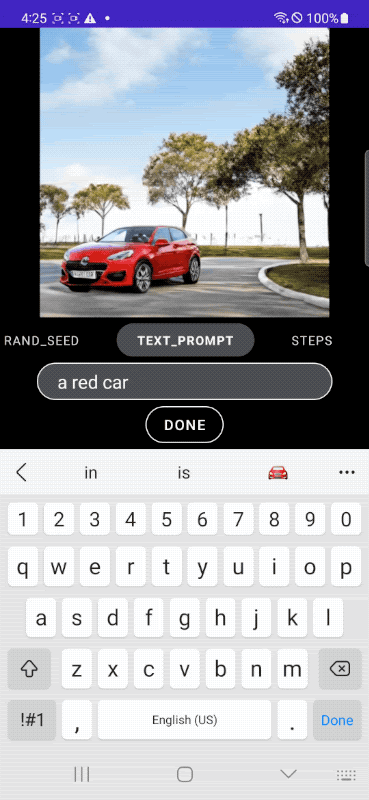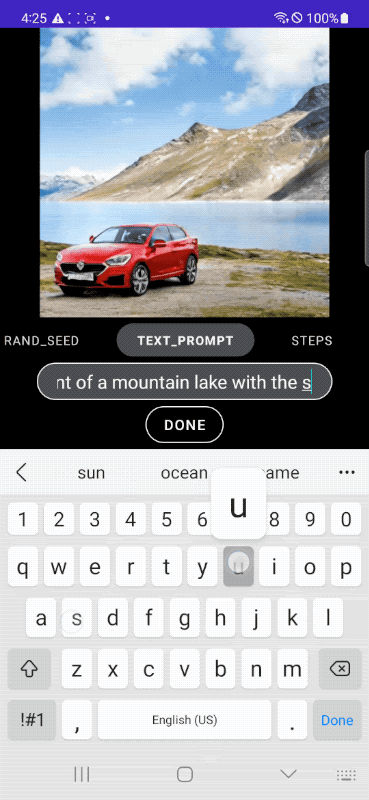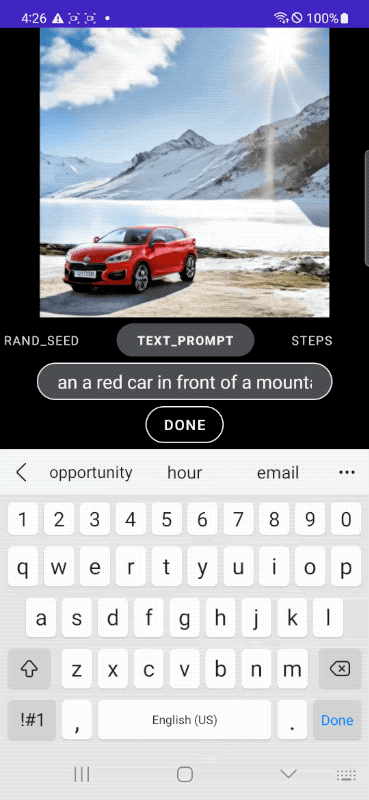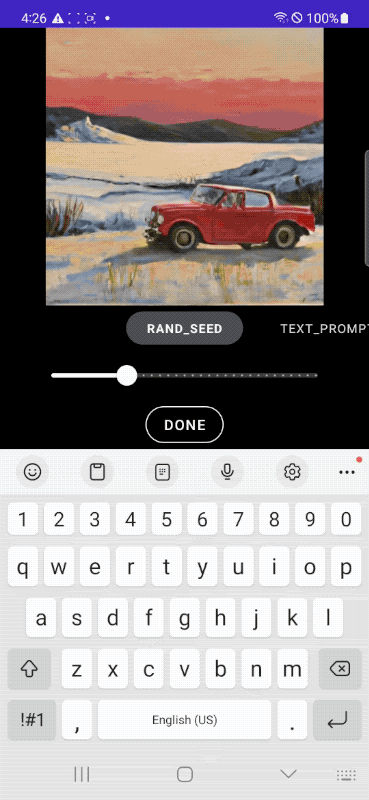
Take the application example presented by Google: as you can see, the user asks MobileDiffusion to generate an image of a car. Simply by modifying the prompt, you can change the scenery, background, colors, image style and any other feature. With the ability to instantly access the visual result.
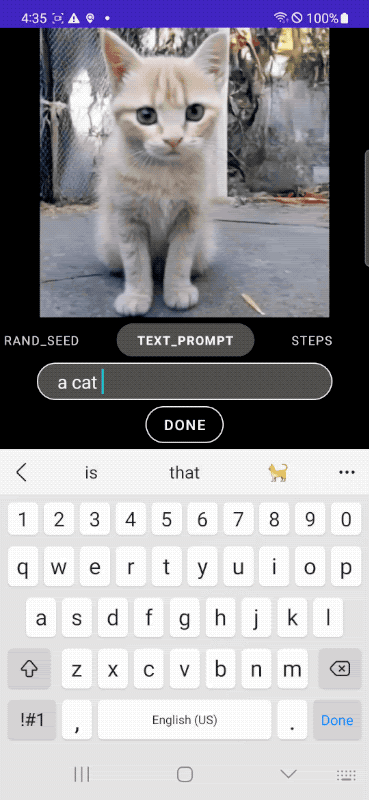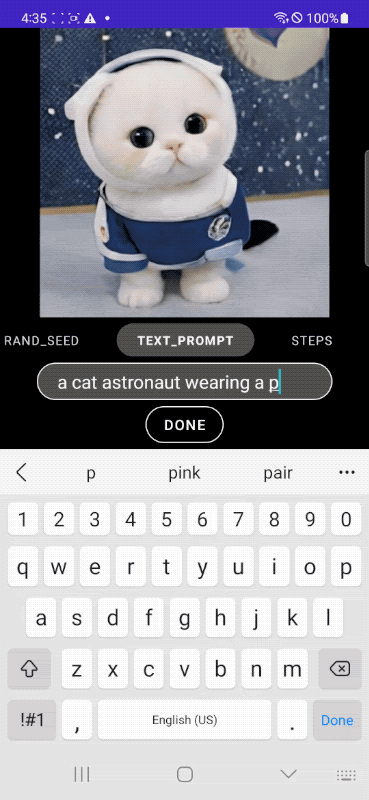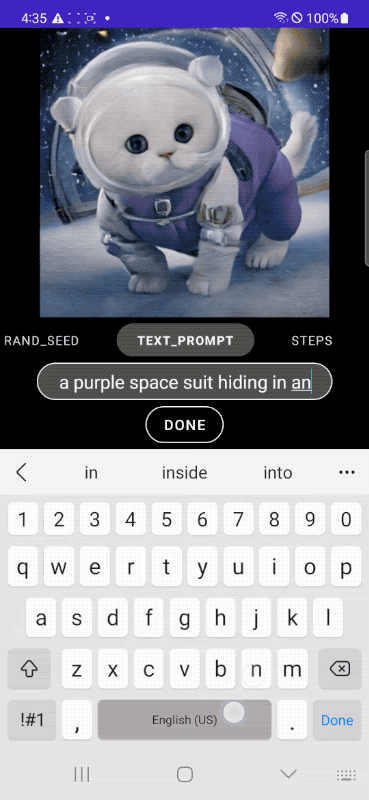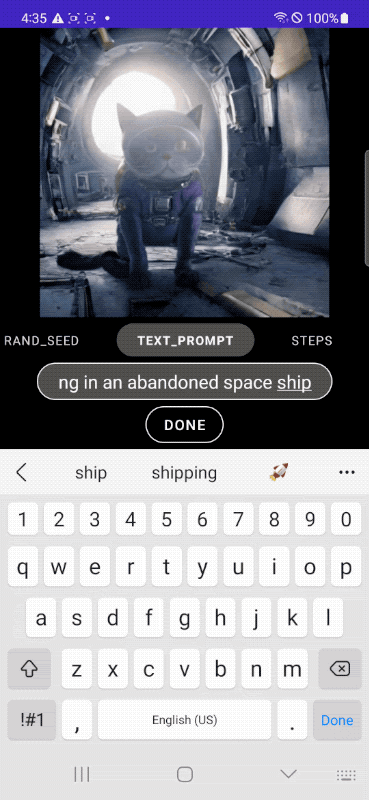
In the following example, we start from the classic image of a cat to then put the feline in an astronaut suit, place it in a spaceship and, finally, add some more detailed descriptions that directly affect the context.
The images published in the article are from Google and are taken from the post “MobileDiffusion: Rapid text-to-image generation on-device“.
Opening image credit: iStock.com – da-kuk