
As part of theartificial intelligence (AI), the concept of Transformer – presented by a group of Google engineers in 2017 – has literally revolutionized the landscape of generative models. These models, at the basis of the functioning of sophisticated chatbots such as ChatGPT, are based on a key concept: theAttention (attention).
And modern Large Language Models (LLM) perform a fundamental task: they read a sentence and search predict the next word. This process involves breaking sentences into called units token and processing these tokens via language models. The Transformers, in particular, protagonists of the historic document “Attention Is All You Need” stand out for their ability to take into due consideration the context in the representation of each token, thanks to the concept of “attention”.
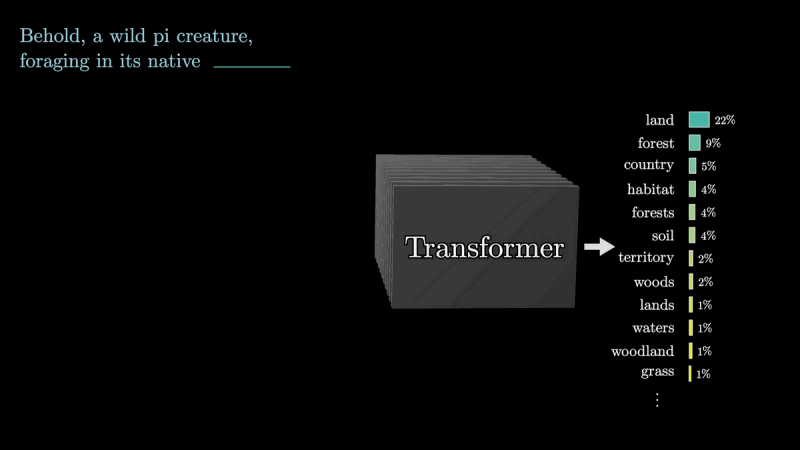
How attention works in the generative models that govern artificial intelligence
3Blue1Brown has published a video guide that illustrates, step by step, the attention mechanism, explaining how it is responsible for the correct functioning of modern generative models and allows you to obtain quality sentences in response to any kind of input.
As we highlighted earlier, a sentence is divided into multiple called units token: LLMs are responsible for processing these units. In reality a token does not correspond exactly to a single word but in the video, to make things simpler, this approximate view is offered.
L’embedding represents the first step in processing a token. This process associates each token with a multidimensional vector: These vectors reflect semantic associations, allowing the model to understand the relationships between words.

Due to their nature, carriers help extract the meaning intrinsic to words (we also talk about it in the article dedicated to Vector Search Oracle). However, the meaning of a word can vary depending on the context, requiring attention to adapt theembedding to various specific situations.
Role of attention in embedding activities
Observing it vector spaceit will obviously be discovered that words with a “compatible” meaning (semantically similar), such as “daughter son” e “woman-man“, are characterized by very similar vectors.
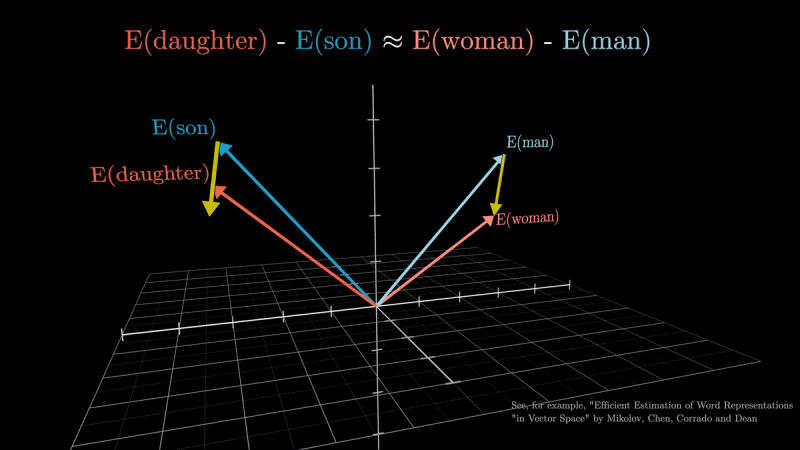
Attention allows you to calculate how “relevant” i nearby tokens (think of the words that make up a sentence) by regulating the embedding consequentially. Thanks to attention, therefore, the generative model can discern between different meanings of the same word or words paired together with others, such as “torre” e “Torre Eiffel“.
In Transformers, attention is computed through a series of steps. For the same single word, therefore, attention allows us to generate a vector appropriate based on the context surrounding. In some cases, attention may arise more relevant meaning from rather distant words, or it can be satisfied with the vectors that characterize nearby tokens.

After a large number of carriers are passed through a network containing several attention blocksthe last step provides to “predict the next word”.
The concept of weight
In attention mechanisms, the concept of “weight” is critical. Weights are used to determine how much a certain portion of theinput (il prompt provided by the user) is relevant to the production of theoutput.
Imagine you have a sentence as input and you want to generate the text to provide to the user as answer. This operation unfolds through the subsequent generation of a series of words, one after the other. To do this, the model must decide which parts of the sentence to focus its “attention” on, i.e. a which words/tokens to give more importance to to correctly generate the next word.
Attention weights indicate just how much weight to give to each input word. These weights are calculated using functions of scoring, which evaluate the relevance of each word to the next word to be generated. Words that are more relevant for the generation of the next word will be characterized by higher weights, while those that are less relevant by lower weights.
L’attenzione single-headed e multi-headed
The “single-headed attention” and the “multi-headed attention” are variants of the attention mechanism. In the first case, the model uses a single attention mechanism to calculate the weights between the input words and the words to be generated as output. This approach has the advantage of simplicitybut may limit the model’s ability to capture complex relationships between words.
The multi-headed attention, vice versa, focuses on different parts of the input text. Each output is then concatenated and combined to form a richer and more complete representation. This is a much more powerful scheme because it allows the model to consider relationships between words from multiple perspectivesimproving the model’s ability to capture meaningful information.
In general, vectors are used to represent both input and output in generative models and are critical for calculating attention weights, which determine which input is relevant for a given output.
Attention weights allow the model to focus on most important parts of the input for the generation task. The weight assignment process is guided bylearning during the phase training of the model: it is in this (onerous) initial phase that the model learns to automatically determine which parts of the input are most relevant for producing the desired output.
In conclusion, attention is at the heart of modern Transformer-based generative models. The mechanism allows the model to “understand” and generate coherent and contextually relevant texts. The use of attention is fundamental for the development of increasingly sophisticated artificial intelligence and “contextually aware“.
The images in the article are taken from the 3Blue1Brown video. Opening image credit: iStock.com – Userba011d64_201