
In April 2024, Meta took it a step further by offering what it presents as the Large Language Model (LLM) most advanced currently available on the scene. It’s about Llama 3, a powerful language model pre-trained and optimized with 8 billion (8B) and 70 billion (70B) parameters, depending on the version. For this reason it is suitable for a very wide range of possible application fields.
Compared to its predecessor Llama 2, its operation is based on a data set that is seven times larger and which, above all, also includes non-English data high quality in over 30 languages. A solid one pipeline Of data filtering is aimed at ensuring the highest quality of training data, which combines information from different sources.
Unlike other proprietary models, Llama 3 uses a open approach and can also be used to develop commercial projects, without problems in terms of licensing.
While, as we demonstrate in our article, the phase of inference is rather easy, creating the Llama 3 model required immense computing power, with Meta engineers using a battery of NVidia H100 GPUs (over 24,500).
How to run Llama 3 locally with LM Studio
Per try Llama 3 locally from a Windows-based system, we suggest downloading and installing the open source LM Studio software. We talked about it together with To be in the article focused on how to run LLM on your systems using a graphical interface.
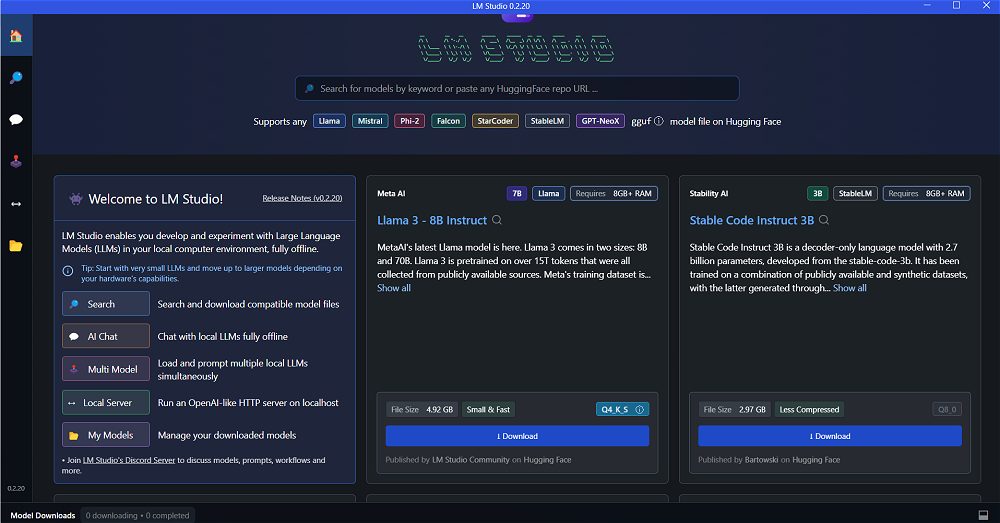
From the first launch, LM Studio declares its compatibility with a wide range of LLMs, including recent ones Llama 3 8B e 70B. Using the search box above or the boxes presented just below it, you can choose the generative model (or the models!) you want to use. To reduce the weight of the data to download, for example, let’s try to select Llama 3 – 8B Instruct authorizing the download of almost 5 GB of information.
Start chatting with the downloaded model locally
Once the model download procedure has been completed, the button AI Chat located inside the left column, allows you to start a conversation in a very similar way to what happens with ChatGPT. The difference is that, in this case, no data is transferred to remote servers and all the information always remains stored locally.
If you have downloaded multiple LLMs locally, LM Studio allows you to choose the one you want to use each time to start a chat session.
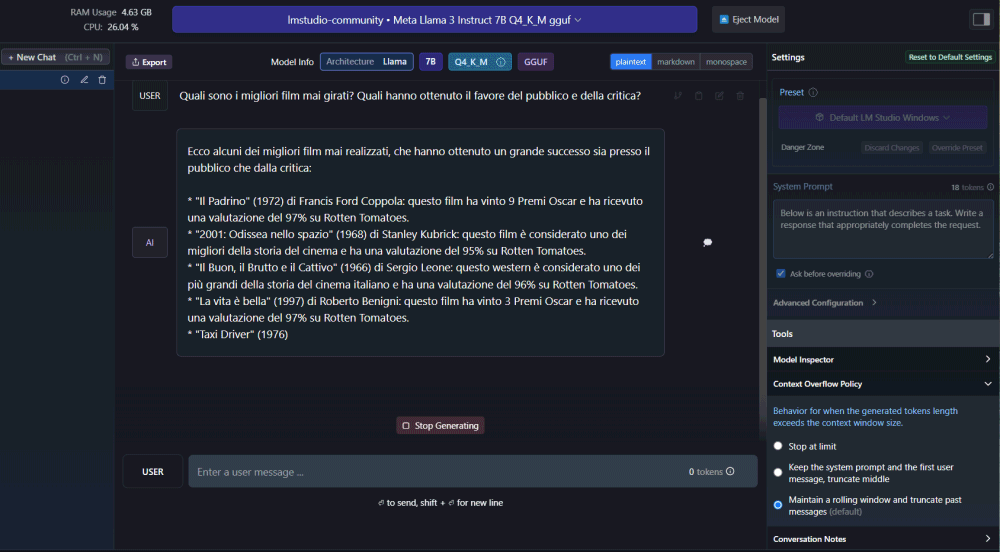
At this point, using the field Enter a user message below, you can get started chat with Llama 3 (as with other models) to verify the quality of the answers offered depending on the inputs (prompt) passed to the system.
Use the APIs to communicate with LM Studio
One of the best features of LM Studio is the API support (Application Programming Interface). This is a feature that, evidently, winks at developers by allowing them to interact with the various models downloaded locally from your applications.
The process is very simple: just click Local Serverbutton in the left column, specify the LLM to use and let LM Studio start a server component dedicated, by clicking on the button Start Server.
By default, you can talk to the LM Studio server using the protocollo HTTP on port 1234. However, you can customize the behavior of the server as you see fit.
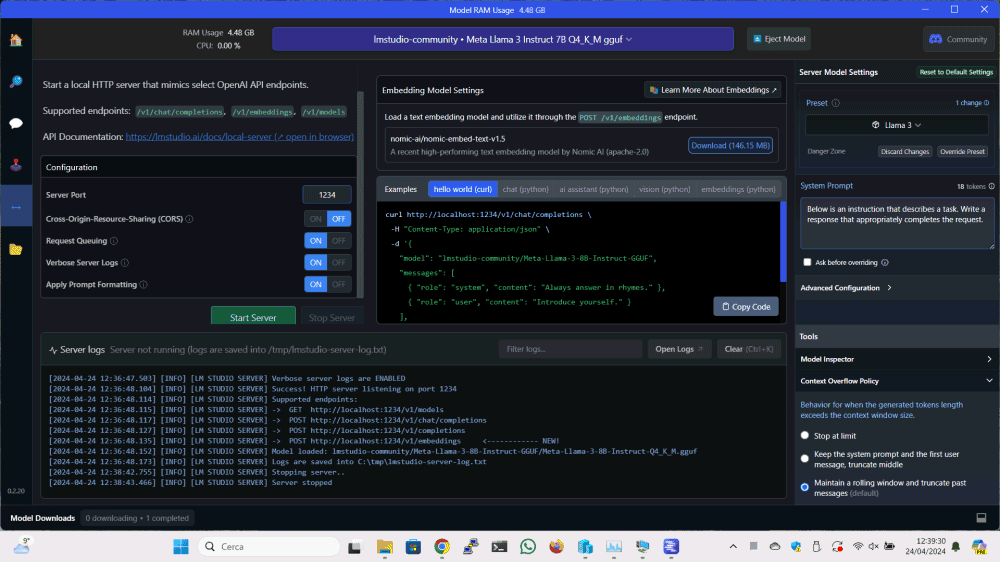
In the box Examplesthe program provides some examples of programming code ready to use, to use in your own projects to send a prompt to the chosen model and get a response output that is, a relevant and precise argument.
Without bothering development, you can also perform simple tests using the curl command line utility. For example, with the following command you can get the list of models installed through LM Studio:
curl http://localhost:1234/v1/models
In the example we refer to the local machine localhost but, obviously, by appropriately modifying the Windows firewall configuration, you can also query LM Studio from other systems on the local network. More information is available in the LM Studio Server support article.
How to run Llama 3 on a Raspberry Pi 5 board
In the article cited at the beginning, we presented Ollama WebUI that is, the version equipped with a graphical interface of a popular one tool based on CLI (command-line interface) which allows you to interact with any open source generative model available today.
We have spoken extensively about Ollama and the possibility of bringing AI to your systems in the past. Since To be is compatible with Llama 3 and that the application is also distributed in a Linux version, you can think of using it for example on a Raspberry Pi 5 board.
Simply access the terminal window of the operating system you installed on Raspberry Pi 5 then type the following commands:
curl -fsSL https://ollama.com/install.sh | sh
ollama run llama3
The second command, when executed for the first time, requests the local download of the Llama 3 model, then preparing it for use with Ollama. In the following steps, the same command simply indicates to Ollama the desire to use the Llama 3 model. The subsequently presented prompt awaits the application to be passed to the LLM.
For further information, you can refer to our in-depth analysis on Ollama: those wishing to use a more attractive and practical Web interface can finally install Ollama WebUI.
Also in this case the dedicated REST API allows you to talk to Ollama and with the underlying LLM Llama 3 from other applications running on the same system or on other devices. By default, theFire at Ollama is listening on port 11434: this means that you can leave the Raspberry Pi 5 board connected to the LAN and interact with the knowledge base of Llama 3 in client-server mode from other devices.
Opening image credit: Copilot Designer.