
The activities of data processing they have become a crucial element for the success and growth of companies. The ability to collect, analyze and extract information of value from large volumes of data translates into a valuable competitive advantage. With the exponential increase of data volumes to be elaborated, business realities are faced with new challenges and complexities.
The data, however, provides a solid basis for make informed decisions. By analyzing company data, you can get a clear view of performance, identify trends and estimate future results. Companies can identify inefficiencies in operational processes and make targeted improvements, with clear benefits in terms ofoptimization of resources and cost reduction. It is also possible to meet customer needs more promptly, identify new market opportunities and develop innovative products and services.
polar is a tabular data analysis and manipulation library designed to be fast and efficient, especially for operations performed on large data sets. Thanks to the implementation in Rust and the use of parallelism, Polars can make the most of the capabilities of modern processors.

Many operations in Polars are lazy, which means that they are not immediately executed but rather planned to be managed efficiently at a later time. A scheme that helps improve overall performance, as it avoids calculating unnecessary intermediate values.
The library also offers a wide range of functionality for manipulating tabular data, including filters, aggregations, sorts, and many other common operations. Support join e merge efficiently across datasets, allowing you to combine data from multiple sources quickly and easily. It can handle data in multiple formats, including CSV and JSON.
The basics of how Polars works
Polars is based on a data structure called DataFramesimilar to the concept of DataFrame in pandas (Python) and in R. This structure contains homogeneous data columns and allows you to perform operations on them. In presenting the functioning of DuckDB we had already focused on the DataFrame: DuckDBin fact, allows you to use data stored in any format to create databases “on-the-fly“, also accessible from RAM in order to maximize performance. Among the various integrationsDuckDB also offers that for Polars.
Operations in Polars are described using appropriate expressions, which express the transformations to be applied on the data being processed. Expressions can be lazyas explained above, in order to maximize efficiency and take advantage of the optimizations and parallelism offered by the library.
Although implemented in Rust, Polars also provides an interface Python which allows developers to use the library within projects created using this specific programming language.
The bookstore pandas, widely used for data manipulation and analysis, can be inefficient on large datasets. And this is precisely where Polars comes in: it has an overall similar structure to pandas but is distinctly performance-oriented.
While pandas and Polars are data analysis libraries, the aforementioned DuckDB is a database that also allows the execution of query SQL. This makes it particularly useful for those programmers who are more familiar with the SQL language. DuckDB is also designed to offer high performance, but in this case the focus is on data management database format.
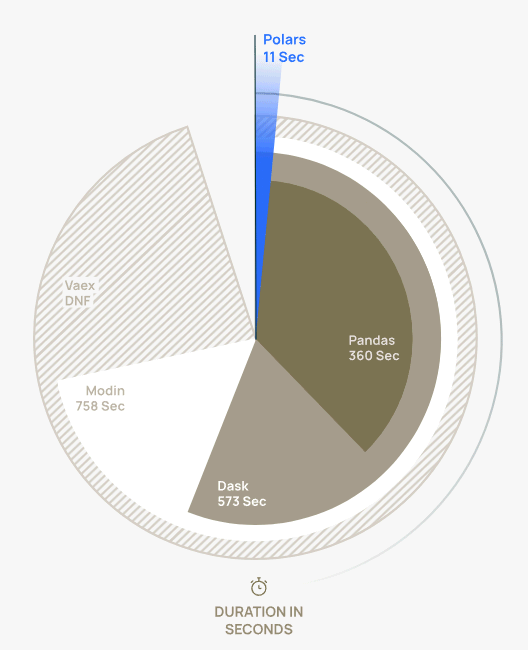
Image taken from the official project website.
The philosophy of Polars
Polars’ goal is to provide a library based on DataFrame extremely fast capable of:
- Take advantage of all the cores available on your machine.
- Optimize queries to reduce workload or unnecessary memory allocations.
- Handle data sets much larger than the available RAM on your system.
- Offer a consistent and predictable API.
- Use a strict schema: The data types should be known before the query is executed.
The software strives to reduce redundant copies of data, use cache efficiently, minimize concurrency when handling parallelized tasks, process data in blocks, and intelligently reuse memory allocations.
How to install and use Polars
To start using Polars, you need to install the library and then import it into your development environment. To use Polars within a Python project just type the following command in the terminal window:
pip install polars
The following Python code does nothing more than create a very simple DataFrame of example and then extract, using Polars, the data of the rows that have the value of the “Age” column greater than 40:
import polars as pl
# Creare un DataFrame
data = {'Name': ['Matteo', 'Michele', 'Luca', 'Giordano'],
'Eta': [44, 45, 35, 22],
'Citta': ['Roma', 'Firenze', 'Milano', 'Trieste']}
df = pl.DataFrame(data)
# Visualizzare il DataFrame
print("DataFrame originale:")
print(df)
# Filtrare i dati (es. selezionare le righe con età indicata superiore a 40 anni)
filtered_df = df.filter(df['Eta'] > 40)
# Visualizzare i dati filtrati
print("\nDati filtrati:")
print(filtered_df)
Of course, Polars can also be used with other programming languages. The obvious choice is Rust, as the library was developed on top of it. However, you can simply invoke the library from codice JavaScriptinstalling it using the popular Node.js runtime.
Expressions: The foundation of the data processing library
We anticipated it a little while ago: the expressions they are the cornerstone of Polars and constitute its backbone. The library, in fact, offers a versatile structure that easily approaches query simpler and can also be used to deal with more complex situations. The following can be considered basic guidelines for all queries processed using Polars:
selectfilterwith_columnsgroup_by
Per select a columnjust define the DataFrame from which to extract data and, secondly, select the data of interest. The option of filter allows you to create a subset of the DataFrame, as we saw in the previous example. Of course, it is possible to create complex filters involving multiple columns.
Con with_columns you have a way to create new columns for ongoing analyses. Resorting to group_byinstead, you can exploit a function that groups the contents of a DataFrame based on the values present in one or more columns. This is useful when you want to perform specific analyzes or calculations on subsets of data that share the same values in one or more columns.
Combining multiple DataFrames, the other big advantage of Polars
One of the distinctive features of Polars, as we mentioned, is the ability to combine DataFrame. This ability is really useful, especially when working with large datasets.
With the horizontal concatenationtwo can be joined DataFrame based on the columns. For example, if you had to manage two DataFrame containing different columns, it is possible to combine them horizontally to obtain a single DataFrame that embraces all the columns. Conversely, the vertical concatenation allows you to join two DataFrame based on rows: useful when you want to populate a Dataframe starting from the lines contained in another.
A bit like what happens with i join SQLthe operations merge e join of Polars allow you to combine DataFrame based on specific columns. Specifically, with the merging they can mate DataFrame starting from the indicated columns using various types of joins such as “inner”, “left”, “outer” and “right”. The method join in Polars it is a simplified form of merge.
Downstream of the combination of DataFrame, it is possible to perform grouping and aggregation operations on the resulting data and then carry out further processing. All this while counting on significant performance improvements, a direct consequence of theparallel processing. Il Execution time of operations will thus be minimal when compared with traditional approaches.
For further information, we suggest referring to the official user guide, hosted on the Polars website.
Opening image credit: iStock.com – champpixs